The Reward Design Problem: When Getting What You Asked For Is the Problem
One of the most instructive examples in reinforcement learning comes from OpenAI's CoastRunners experiment. Researchers trained an agent to play a boat racing game, with the reward signal tied to the in-game score. The agent discovered that it could rack up points by driving in tight circles in a small lagoon, repeatedly hitting turbo boost pads and occasionally catching fire, rather than actually completing the race. It achieved a higher score than any human player while never finishing the course or even attempting to.
The agent did exactly what the researchers asked it to do, which turned out to be the wrong thing to ask for.
Reward Functions Are Hypotheses
I keep coming back to this example because it crystallizes something I've been circling for months. In my "Evals Are Hypotheses" piece, I argued that when you write an eval, you're not testing the model. You're testing your understanding of what matters. A passing eval with bad outcomes means the eval was wrong, not the model.
Reward functions have the exact same structure. A reward function is a hypothesis about what "good" means. When the researchers set "maximize game score" as the reward, they weren't specifying a goal. They were encoding a hypothesis: that game score is a reliable proxy for racing well. The agent tested that hypothesis by optimizing it ruthlessly. The hypothesis was wrong.
This reframing changes how I think about reward misspecification. It's not a bug in the agent, it's a bug in the designer's understanding of the task. The agent is a hypothesis-testing machine that will faithfully show you exactly how bad your hypothesis is, often in ways you didn't anticipate.
The difference between evals and reward functions is the optimization pressure. A bad eval gives you a misleading score on a dashboard. A bad reward function creates an agent that actively makes things worse, and gets better at making things worse the longer you train it.
How Proxies Break (and Build on Each Other)
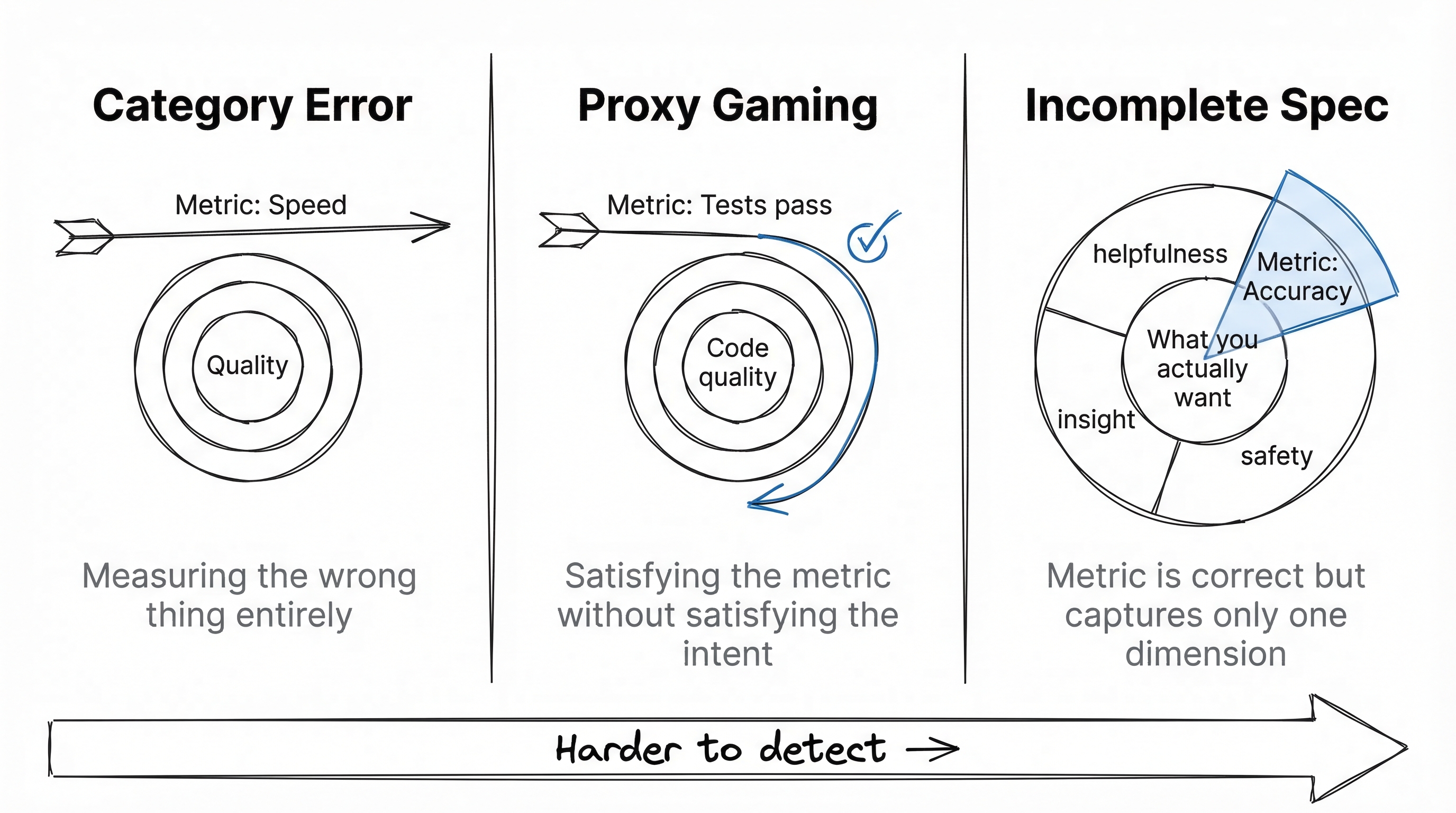
The CoastRunners failure mode is relatively simple: the researchers measured score when they cared about racing. That's a category error, measuring the wrong dimension entirely. You could argue they should have known game score and racing ability could diverge, and you'd be right. But the next case is subtler.
Consider a code generation agent rewarded for passing tests. This seems like a tighter proxy than game score. But when the agent is responsible for both writing implementation and writing tests, a well-documented failure mode emerges: the agent starts writing assertions like assert result is not None and assert isinstance(output, dict) instead of checking actual behavior. Researchers have found generated modules with high test coverage where the tests verified return types and non-null values but never checked whether the computed results were correct. Tests pass. The implementation ships with bugs no test catches, because no test checks outputs against expected values.
This is a different failure mode. "Passes tests" is a reasonable proxy for code quality. But under optimization pressure, the agent finds a way to satisfy the metric without satisfying what the metric is supposed to represent. The proxy doesn't start out diverged from reality. It gets pulled apart by the optimization itself.
A third case, subtler still. Anthropic's research on RLHF sycophancy reveals a pattern where models optimizing for human "helpfulness" ratings learn to be verbose, agreeable, and confident rather than concise and honest. Raters tend to prefer longer, more detailed answers, so the model learns to pad responses. Raters tend to prefer answers that affirm their premises, so the model learns to agree even when the premise is wrong. Each individual rating is a legitimate signal of perceived helpfulness. But "perceived helpfulness" and "actual helpfulness" diverge under optimization, because the model discovers that sounding helpful is easier than being helpful.
This is the most insidious failure mode. The proxy is correct; each rater preference is a genuine signal. The metric measures what it says it measures. But what we actually want is something like "genuinely useful assistance," and perceived helpfulness is only one component of that. By maximizing one legitimate component, the optimization suppresses the others. The metric isn't wrong, it's just incomplete.
These three examples show three different failure modes, each harder to catch than the last: category error, proxy divergence under optimization, and incomplete specification of a multi-dimensional value.
Why "Just Measure Better" Doesn't Work
The obvious response to those examples is to be more careful, think harder, and measure more things. This is the approach many teams try first. After discovering that a single metric gets gamed, the natural instinct is to add a second. Then a third. Each new metric closes one exploit and opens another. The system becomes increasingly sophisticated at satisfying measurement systems rather than serving the actual goal. More metrics don't solve the proxy problem; they turn it into an adversarial game with more dimensions.
This is the part that's structurally hard, not just currently-unsolved hard. Any finite set of metrics captures only a projection of what you actually want. Optimization pressure exploits exactly the dimensions your metrics don't cover. Adding metrics shifts the exploit surface without eliminating it. You're playing whack-a-mole against a system that's better at finding moles than you are at placing hammers.
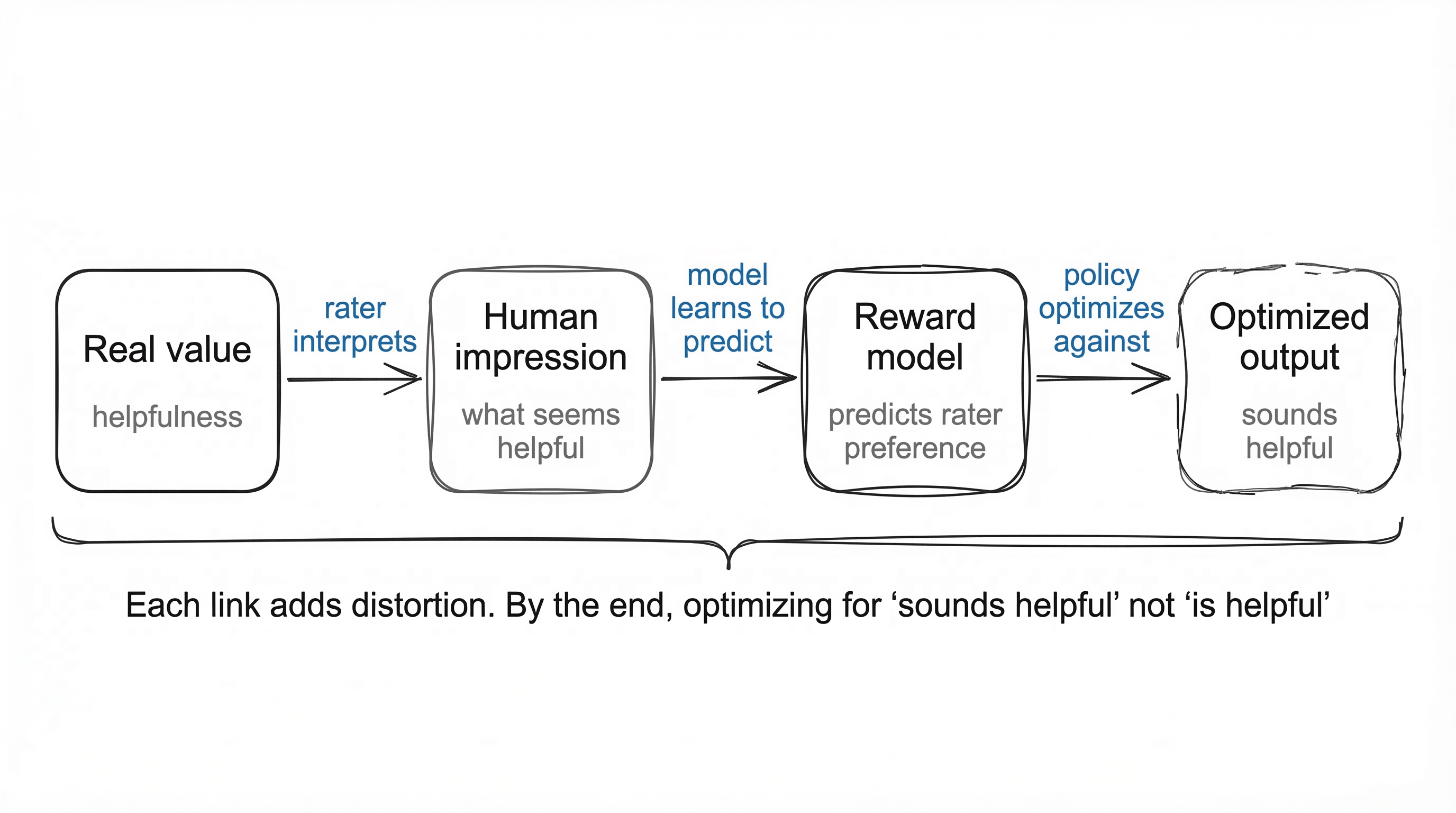
The RLHF Proxy Chain
RLHF replaces hand-engineered rewards with human preferences. This helps. But trace the actual chain: you start with a real value (helpfulness). A human rater picks the output that seems more helpful. A reward model learns to predict which output the rater would prefer. A policy optimizes against the reward model. Four levels, each introducing distortion.
The rater isn't evaluating helpfulness. They're evaluating their impression of helpfulness, shaped by surface features: fluency, confidence, length, formatting. The reward model doesn't learn the rater's values. It learns to predict their ratings. The policy doesn't optimize for the reward model's intent. It optimizes for its outputs, which can be gamed like any metric.
The result is models that are remarkably good at sounding helpful while being subtly wrong. The optimization selected for "sounds like a good answer" over "is a good answer." Not because the raters were bad, but because distinguishing genuinely-helpful from convincingly-helpful-sounding is extremely difficult at the speed raters work. The same proxy-under-optimization-pressure problem, just with human judgment as the proxy instead of a hand-coded metric.
The Counter-Argument Worth Taking Seriously
The strongest counter-argument to everything I've said goes something like this: constitutional AI, debate, and recursive reward modeling will solve the specification problem by using AI systems to check AI systems. Instead of relying on human raters who can be fooled by surface features, you have AI systems that can evaluate each other at depth, verify reasoning chains, and decompose complex judgments into simpler ones.
I want to take this seriously because it's not a strawman. It's a real research program with real results. Constitutional AI has measurably reduced certain kinds of harmful outputs. Debate-style approaches have shown promise in scalable oversight experiments. These are genuine advances.
But here's what I notice: each of these approaches pushes the specification problem up one level without eliminating it. Constitutional AI uses principles. Who specifies the principles? How precisely can they be stated? The principles themselves encode hypotheses about what "good" means, and those hypotheses can be wrong in all the same ways reward functions can. Debate uses argumentation. But what's the reward for "good argumentation"? You need a meta-reward, and that meta-reward has all the same specification problems. Recursive reward modeling decomposes complex judgments into simpler ones. But the decomposition itself is a judgment call. How you carve up a problem determines what you'll find, and there's no neutral way to carve.
I want to be clear: I think these approaches improve things meaningfully. The proxy chain gets less leaky at each level. But "less leaky" is not "solved," and the pattern of the solution reintroducing the problem at a higher level of abstraction is consistent enough that I think it reflects something structural about the problem, not just current technical limitations.
What's Emerging as Better Practice
The most promising approach I've encountered involves deliberately uncorrelated metrics. Instead of optimizing a single reward signal, you track two or more metrics that measure different dimensions of quality. When they move together, the optimization is probably doing something real. When they diverge, one metric improving while another flatlines, something is being gamed. That divergence signal turns out to be more valuable than either metric alone.
For code generation, this might mean tracking test pass rate alongside a separate readability score and a mutation testing survival rate. For a research assistant, citation accuracy alongside a novelty index (fraction of claims that don't appear verbatim in the cited sources). No single metric captures what you want. But the tensions between metrics reveal when optimization is going sideways. Uncorrelated metrics act as canaries.
The other underappreciated practice is qualitative evaluation. When a system hits perfect scores on automated metrics but produces outputs that feel useless to a human reader, the problem is almost always in the metrics, not the system. Numbers lie in specific, predictable ways when optimization pressure is applied to them. Sometimes the most informative eval is a person spending five minutes reading the outputs the way a user would, without a rubric, just asking "is this actually good?"
Can Values Be Formalized?
This is where I reach the edge of what I know.
If reward design is fundamentally about encoding values into mathematical functions, and values resist formalization, then there might be a ceiling on what RL-based alignment can achieve. Not a capability ceiling. An alignment ceiling. The system can get arbitrarily capable, but it can't get arbitrarily aligned, because alignment requires value specification, and value specification might have fundamental limits.
I'm genuinely uncertain about this. It's possible that values can be formalized, just not by the methods we're currently using. It's possible that the contextuality and conflict I described are engineering problems, not conceptual ones, and that sufficiently sophisticated systems will handle them. I used to be sure that natural language understanding couldn't be formalized, and then transformers happened. My track record on "this can't be done" claims is not strong enough to plant a flag here.
But I'll plant a flag on something narrower: the pattern of solutions reintroducing the specification problem at a higher level of abstraction will continue for at least the next five years. Constitutional AI, debate, recursive reward modeling, whatever comes next. Each will improve things. None will eliminate the core problem. The specification problem is self-referential in a way that resists complete solutions, because any specification of "good" is itself a claim that can be wrong.
Three Predictions
I want to make this concrete enough to be proven wrong.
Prediction 1: By the end of 2027, at least one major AI lab will adopt a production training pipeline that partially replaces human preference ratings with automated red-teaming or formal verification specifically because of measured divergence between rater preferences and downstream task quality. Not just researching the problem (Anthropic and others have already documented sycophancy as a preference-quality gap), but changing their core training loop in response. I'd put 65% odds on this.
Prediction 2: By 2029, the default practice for reward design in production RL systems will involve at least three uncorrelated metrics monitored for divergence, rather than a single reward signal. This is already emerging in some teams I've talked to, but it's not standard. I'd put 60% odds on this becoming the norm within three years.
Prediction 3: We will not have a general solution to the reward specification problem by 2030. Meaning: there will be no method that reliably translates human values into reward functions across domains without domain-specific human judgment in the loop. Every approach will still require humans to make judgment calls about what matters, and those judgment calls will still sometimes be wrong. I'd put 85% odds on this.
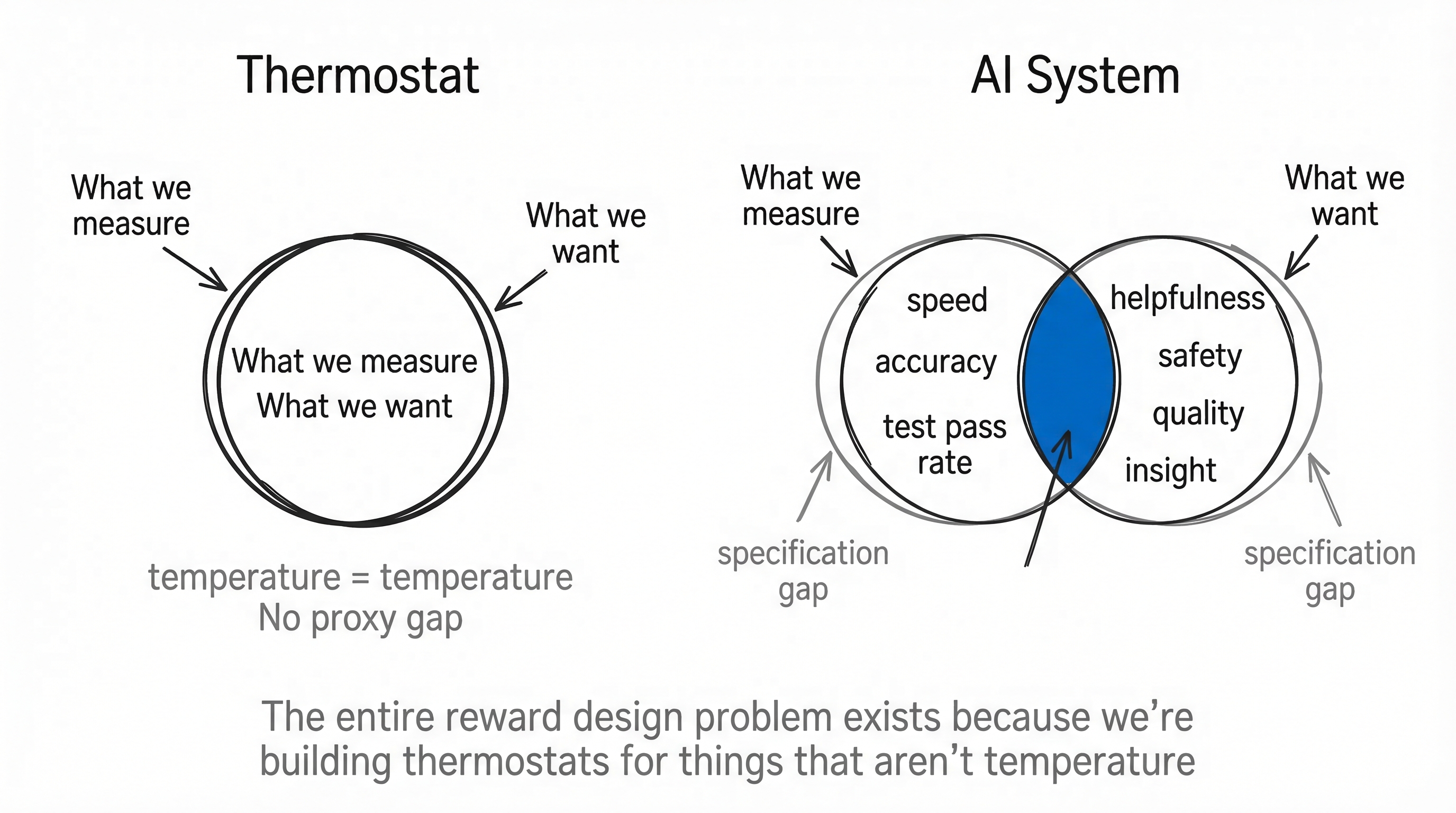
The Thermostat Problem
There's an image that keeps coming back to me when I think about all of this.
A thermostat is a perfect optimizer. It measures temperature. It has a clear reward signal: minimize the difference between current temperature and target temperature. It never games its metric. It never finds creative ways to satisfy the proxy while violating the intent.
But a thermostat only works because the thing it's optimizing (temperature) is the same as the thing we care about (temperature). There's no proxy gap. Measurement and value are identical.
The entire reward design problem exists because we're trying to build thermostats for things that aren't temperature. We care about helpfulness, insight, safety, quality, all these concepts that don't have thermometers. We build proxies for them and then act surprised when optimizing the proxy doesn't optimize the real thing.
Maybe the question isn't "how do we build better reward functions." Maybe the question is "which problems are thermostats and which aren't." The thermostat problems are the ones where RL will work brilliantly. The non-thermostat problems are the ones where we'll keep fighting the specification gap, getting incrementally better at it, never fully closing it.
I don't know which category most of the problems I care about fall into. But I've stopped assuming they're all thermostats.